AgE
AgE environment is being developed as an open-source project at the Intelligent Information Systems Group of AGH-UST. AgE provides a platform for the development and execution of distributed agent-based applications - mainly simulation and computational systems.
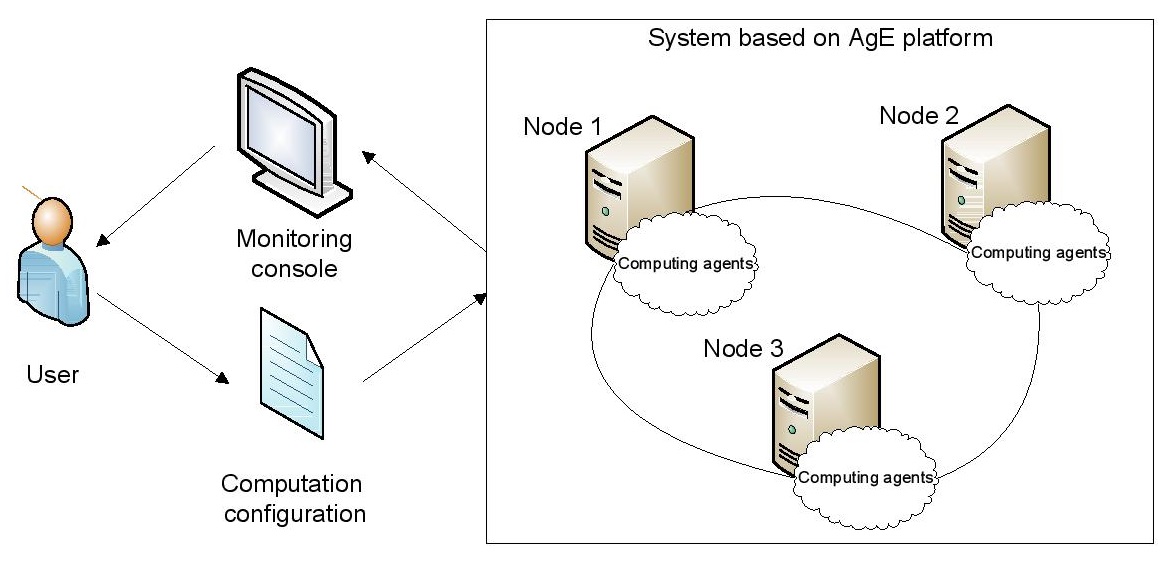
The figure below presents an overview of a system based on AgE platform. A user constructs the system by providing an input configuration in XML format. The configuration specifies the simulation structure and problem-dependent parameters. After the system start-up, the environment (agents and required resources) are instantiated, configured and distributed amongst available nodes where they start performing their tasks. Additional services such as name, monitoring, communication and topology service are also run on these nodes to manage and monitor the computation. The output of the simulation is problem-dependent and may be visualized at run-time by dedicated graphical tools and interpreted by the user.
Structure and execution of agents
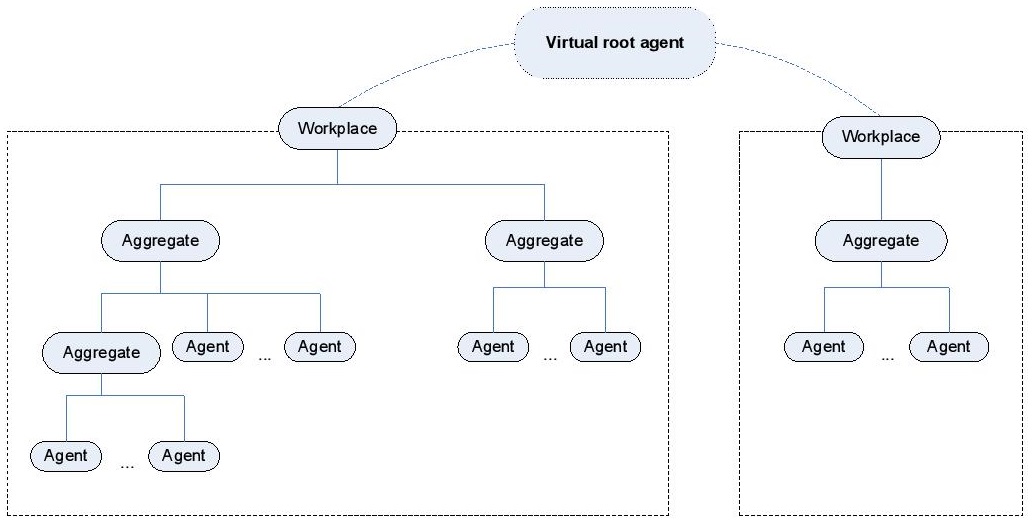
A simulation is decomposed into agents, which represent individuals or parts of or whole populations. Agents are structured into a tree with virtual root agent (as shown in the figure below) according to the simulation decomposition. The top level agents (called workplaces) along with all their children can be distributed amongst many nodes.
Agents can have named properties, which are features of an object, which can be referenced during run-time by its name in order to access, modify or even monitor its value. Properties are defined by annotating fields or methods of agents classes with dedicated Java annotations. Each agent exists in an environment, defined by the parent agent, which provides a context of agent’s processing. With the use of the environment, agents can communicate with their neighbour agents via messages, acquire specific information about them via queries, or even request them to perform specific actions.
It is assumed that all agents at the same level of the structure are being executed in parallel. The platform introduces two types of agents: thread-based and simple. The former are realized as separate threads so that the parallel processing is managed by Java Virtual Machine (similarly to JADE platform). Such agents can communicate and interact with neighbours via asynchronous messages. However, a large number of such agents would significantly decrease the performance of a simulation because of frequent context switching and raises synchronisation problems. Therefore, following the concept of phase simulation, the notion of simple agents is introduced. The execution of simple agents is based on steppable processing which is to simulate pseudo-parallel execution of agents’ tasks. Two phases are distinguished:
- Execution of tasks related to computation semantics in the step() method. In case of an aggregate agent all it’s children perform their steps sequentially. While doing so, they can register various events, which may indicate actions to perform or communication messages, in the parent aggregate.
- Processing of events registered in an event queue. Since events may be registered only in agents that possess children, this phase concerns only aggregate agents.
The described idea of agents processing ensures that during execution of computational tasks of agents co-existing at the same level in the structure (agents with the same parent), the hierarchy remains unmodified, thus the tasks may be carried out in any order. From these agents perspective, they are processed in parallel. All changes to the agent structure are made by aggregates during processing of the events that indicate actions such as addition of a new agent, migration of an agent, killing an already existing agent, etc. They are visible for agents while performing the next step.
Actions
The environment of simple agents determines the types of actions which may be ordered by child agents. It also provides concrete implementations of these actions and thereby supplies and influences agents’ execution. Thus actions realize the agent principle of goal level communication, because agent only lets the environment know what it expects to be done but it does not know how it will be done.
Simple agents request their parent aggregates to execute actions during an execution of a step of processing. Then, all of actions are executed sequentially (in order of their registration) by the aggregate after all children agents finished their operations.
Because some of the actions can significantly change the environment (for example removal or migration of an agent) so that the other actions would become invalid, the following phases have been introduced:
- initialisation (init), when target addresses are verified,
- execution (main), when the real action is executed,
- finalisation (finish), for performing activities that could not be executed during the main phase (e.g. removal of an agent when other agents could refer to it).
All changes of agents structure that can influence execution of other registered actions are performed in the finalization phase. As a result, performing an action in the execution phase is safe. In the initialization phase actions can perform some preparation activities that are required by other actions.
Two types of actions exist:
- Simple actions that can define only one task to be performed on only one agent.
- Complex actions - they are containers for other actions and can hold a tree-like structure. Actions wrapped by them are executed in a well-defined order and allows to create more complicated scenarios like an exchange of resources, when the separate component actions are required for getting a resource from one agent and for delivering it to another.
Most simple aggregate actions are defined as methods in a class of an aggregate agent and the default aggregate implementation provides some actions out-of-the-box:
- adding of a new agent,
- moving an agent to another aggregate,
- death of an agent,
- cloning of an agent.
Moreover, users can extend the platform with any actions they need. These actions can be created as strategies bound to the aggregate using the configuration of the platform. They allow to extend functionality of the platform in an easy way but have a downside of not having the possibility to refer to private members of the aggregate. Decision of how to execute such actions is made by the parent agent who resolves proper action implementation according to Service Locator design pattern.
Life-cycle management
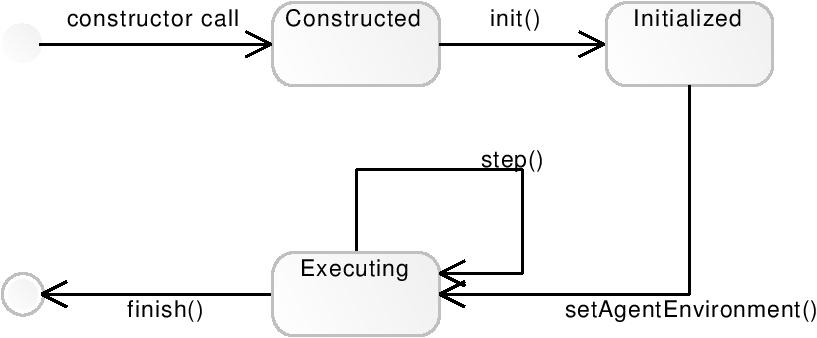
The lifecycle of an agent consists of the following phases:
- Construction - when a constructor of agent class is called.
- Initialisation of the object dependencies and properties - when the init() method is called; at this point the agent has all its dependencies injected by the component framework based on dependency injection pattern mechanism. Also its properties are initialized using the component framework or by agent itself. For example at this stage, an agent generates an address.
- Initialisation of the environment - the moment when the parent of the agent calls the setAgentEnvironment() method. At this point the agent can use mechanisms that requires the existence of the local environment i.e. actions, queries, messaging.
- Finalisation of the agent - the finish() method. The agent should finish its operation at this point.
Threaded agents additionally provide the run() method, called by the Java Virtual Machine after their dedicated thread was started. At this moment they can start the main loop of their execution.
The full lifecycle of the simple agents is shown in the figure below. Simple agents need to provide an implementation of the step. It is done in the step() method. This operation is called in an arbitrary order by the parent aggregate on every agent it contains. The actual execution from the point of view of the whole tree of agents is performed in the postorder way: firstly the aggregate lets children to carry out their tasks and only after they finished them it executes its own tasks.
During the execution of the step, the simple agent usually needs to perform following actions:
- receive and send messages,
- execute queries,
- execute a part of the computation,
- order actions for the parent.
After iterating over all children, the aggregate needs to process the event queue. These events are usually actions requested by the children.
Communication facilities
The platform allows for all agents to have a unique addresses, which allow for their identification and supports inter-agent communication. The particular property of being globally unique is guaranteed by a structure of the address. As shown in the figure below, the agent address comprises of three components: an UUID (Universally Unique Identifier), a node address, and a name. Two former parts identify an agent in the platform instance and the last one is a replacement for an UUID provided for the user convenience (for usage in a user interface or logs).

An address is usually obtained by an agent during the initialisation of the component dependencies. It is done by requesting a new address object from the AgentAddressProvider instance that is a local component of a node.
Communication via message passing
Agents located within a single aggregate can communicate with each other via simple messages.
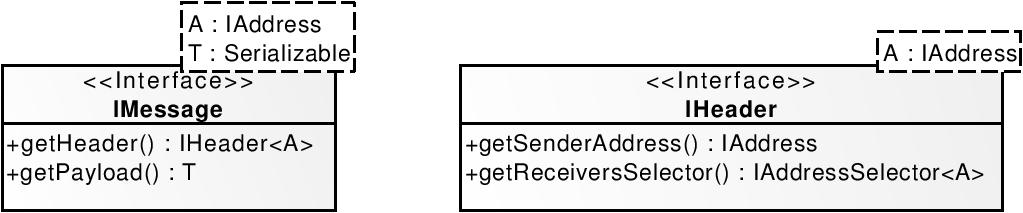
Interfaces used in messages are shown in the figure below. A message defined by the IMessage interface consists of a header and payload. The header, as defined by the IHeader interface must specify a sender of the message (usually the agent that created the message) and its receivers. The payload is simply a data of any (serialisable) type that is to be transported.
Receivers are defined using selectors. They offer a possibility to define receivers with the unicast, broadcast, multicast or anycast semantics.
In the case of simple agents, sending and delivery of messages is performed by an aggregate agent. The sender adds a message event to its parent queue. The parent handles it by locating all receivers and calling a message handler on each of them. These messages are placed on a queue and can be received by the agent during its next step.
Thread-based agents use a similar queue of messages but are not restricted by the execution semantics and can inspect it at any point of time.
Query mechanism
Queries offer a possibility to gather, analyze and process data located both in local and remote (from the point of view of the query executor) components.
The diagram in the figure below shows base classes and interfaces of the query mechanism along with their interconnections. The central point of this mechanism is the IQuery interface. It provides only one method: execute(). A query, as defined by this interface, is an action performed on a target object that leads to creation of query results. Specific implementations define a relationship between the target and results.
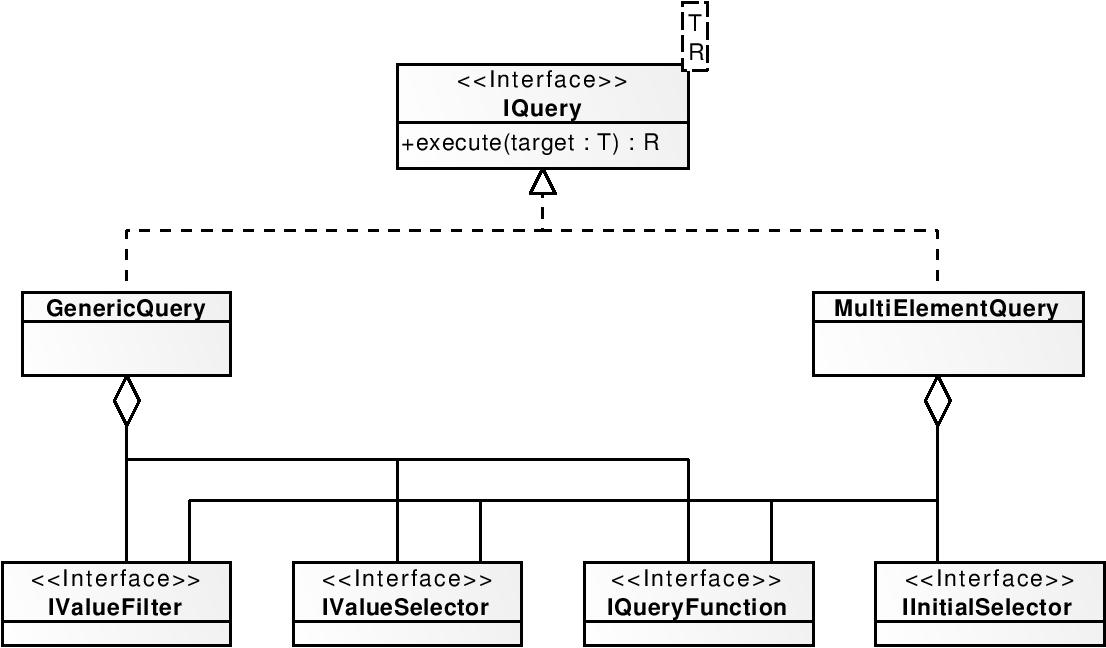
On the top of this interface and definition, a simple, declarative, yet extensible query language is built. Queries are implemented as (GenericQuery and MultiElementQuery classes in the diagram above. It allows the user to perform tasks like: computation of the average value of some chosen properties from the agents in the environment, select and inspect arbitrary objects in collections and much more.
The following operations are defined:
- Preselection of values from the collection. It is only available if the query is performed over an iterable type instance. Its task is to select some (e.g. first ten or random) of objects without usage of the object-related information.
- Filtering by a value. This is an operation similar to WHERE clause in SQL.
- Selection of values. It can select specific fields from objects and it shows some similarities to the SELECT operation from SQL. If this operation is not defined then whole objects are selected.
- Functions working on an entire result set. They can remove, add or modify elements.
Operators are defined as implementation of specific interfaces (one for every operation, as shown in the diagram above). They are presented to the user as static methods (e.g. lessThan(), pattern() etc.).
A query is built by specifying following properties:
- A type of the target object (the object passed as an argument to the execute method).
- A type of results.
- In the case of collections - a type of elements in a collection.
Such an exhaustive specification is required because queries rely on these pieces of information to control correctness of operators used by the user (with the usage of Java generics). Moreover, queries in AgE are built without the knowledge of the target object (it is in opposition to many similar mechanisms like LINQ).
After that, an operation of the query is specified using aforementioned operations. The execution of the query is carried out by calling the execute() method.
The following Java code shows a simple example of how a query can be created and executed. In this case a collection of strings is queried.
CollectionQuery<String, String> q =
new CollectionQuery<String, String>(String.class);
q.from(first(10))
.matching(anyOf(
pattern("li.*"),
pattern("lorem[Ii]psum")));
Collection<String> results = q.execute(someList);
It can be noticed that queries definition uses the fluent interface pattern with specific operations being composed from static methods.
This approach of declaring a query without the knowledge of the target is additionally useful because it allows to execute a single query many times (possibly with caching the results or operations) or to delegate queries to be executed in another location. The query delegation is actually often used within the platform during the operation of querying an environment of a parent of an agent. This mechanism is essential for performing the migration of agents.
The other side of the queries mechanism is the extensibility offered to the user on many levels. It is possible to create completely specialized queries (by implementing the IQuery interface), extending the described declarative mechanism or even define in-line operators when creating a query. This elasticity of queries was very important because of performance requirements resulting from some applications of the platform. An approach was adopted, that the user is able to provide much faster solutions for his specific problems.
In some cases it is also useful to let know a queried object about a query being executed on it. For this reason the interface named IQueryAware was created. By implementing it any object can communicate to the query that it wants to be notified about some events related to the execution. Currently, two events are supported: initialisation and finalisation of the query.
The last part of the queries mechanism is caching. The platform offers a possibility to build a cache of query results. Its expiration time is based on the workplace step counter. This cache works as a wrapper to the query (and as such is an implementation of the IQuery interface). During the execution it checks whether stored results expired and possibly executes a real query replacing old results.
AgE component framework
The platform provides dedicated component framework, which is built on the top of an IoC container. It utilizes PicoContainer framework - a popular open-source Java implementation of IoC container that can be easily extended and customized.
Both agents and strategies are provided to the platform as components. Their implementation classes can define named dependencies to other components (i.e. other agents, services or any other dependent classes) and simple properties that hold for example problem-dependent values. The dependencies definition for a component type, together with class’s public methods (treated as component’s operations) may be perceived as requirements closely related to component contracts.
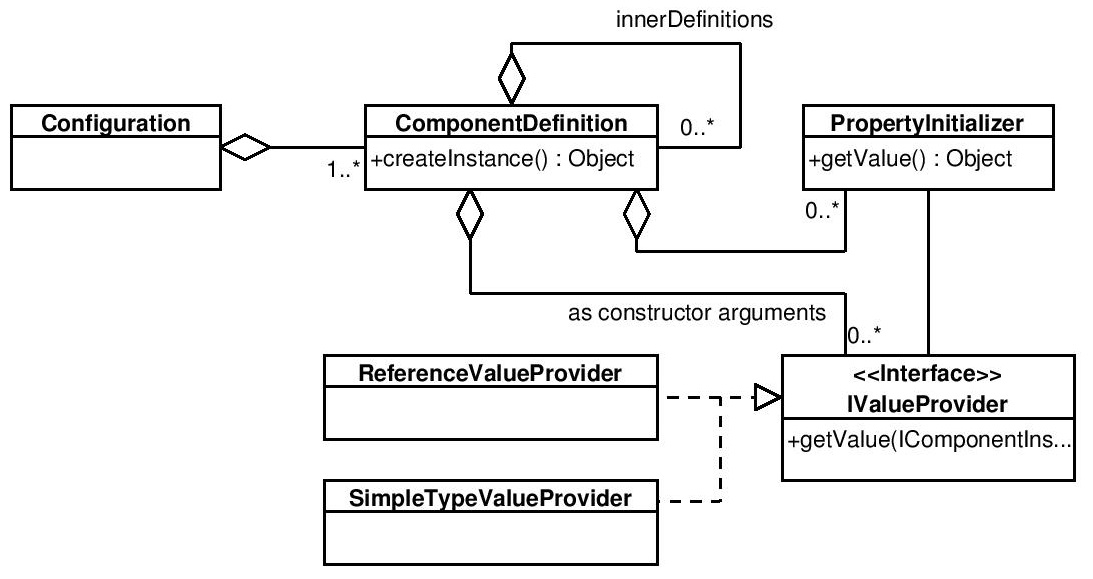
The process of assembling a system is divided into two main phases. In the first one, the input configuration is read from XML file with well-defined structure and further transformed into object configuration model, structure of which is shown in the figure below. A ComponentDefinition instance describes a single component and contains data such as it’s name, type (which is the name of a class) and scope, which is to determine if a new component will be created for each request (protoype scope) or only once during the first request (singleton scope). The definition also specifies the constructor arguments, which are implemented as IValueProvider objects and used during constructor-based injection, as well as property initializers, responsible for initialising component properties with reference or simple values. Moreover, the definition contains createInstance method which creates a new instance of a described component with initialized dependencies (this process is described below). Component definitions may form hierarchical structures (via innerDefinitions). If a definition is a child of another one, it is said to “exist in the context of the outer definition” and is visible only for it’s parent and other parent’s children (siblings). Validation of the model, performed during processing of the input configuration, allows for detecting errors such as unresolved dependencies, non-existent components or incorrect property definitions.
In the next phase of system assembly process, a hierarchy of IoC containers is built according to a structure of component definitions. For each definition a dedicated adapter (CoreComponentAdapter) is created and registered in a container as shown in the figure below. Moreover, the adapter implements the interface, which defines methods for retrieving instances of components by name or type - IComponentInstanceProvider.
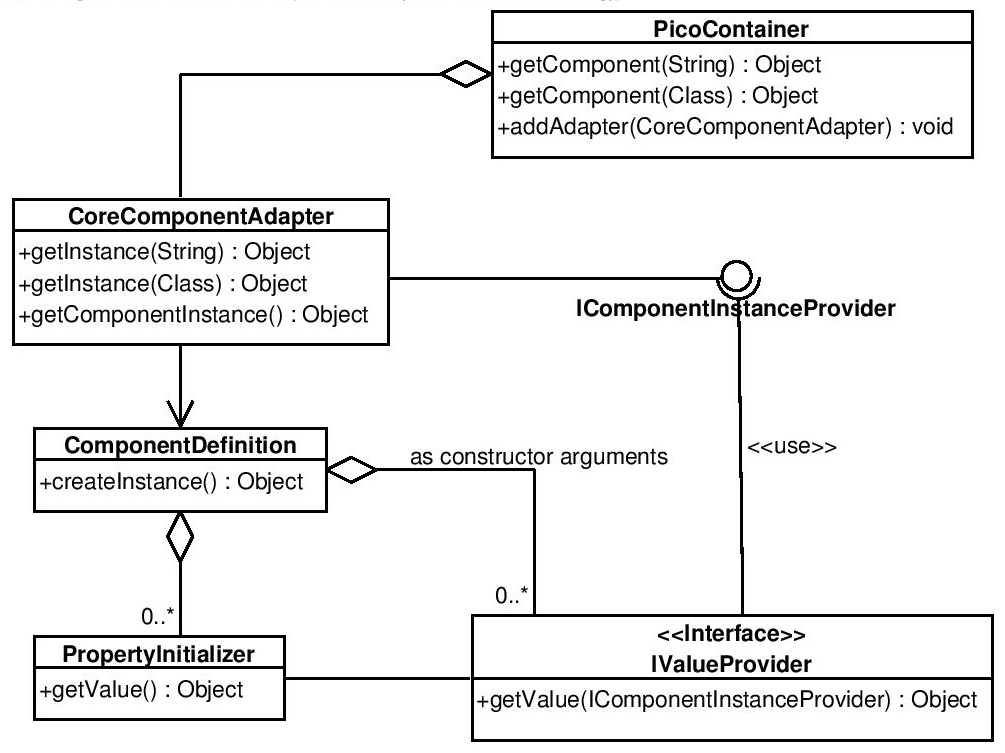
When a request for a component instance is directed to the container, it locates appropriate component adapter (using given name or type) and delegates the request further, to it. The adapter calls the associated component definition’s createInstance method, which is responsible for creating a component instance. While instantiating a component the component adapter retrieves instances of dependent components from associated IoC container (or its parent), and the loop whole process starts again. In the case of simple types, a value is kept directly in a value provider object and is returned on a request. The whole process is repeated until all dependencies are resolved and then the fully-initialized component instance is returned to the client.
The presented mechanism gives a possibility to build various structures of agents with their dependencies and initial properties values based on the input configuration.
Node architecture
The simulation is executed in a distributed environment comprised of nodes connected via communication services. Each node is a separated process being executed on a physical machine. Nodes are responsible for setting-up and managing an execution environment for agents performing a simulation, as well as assuring communication and collaboration in distributed environment.
The main part of the node is a service bus that realize Service Locator design pattern. The bus is realized by AgE component framework, which utilizes IoC container to create and initialize an object that is a run-time instance of a service. Services are being registered in the container by the node boot-strapper or other services, based on component definitions, created using API or read from XML configuration file. A reference to a service instance can be acquired by service name or type via IComponentInstanceProvider interface.
The node distinguishes stateless and stateful services. The former offer functionality dependent only on parameters given in method call, therefore they does not hold any state and are always thread-safe. They are created on demand (at the first reference) and than their instances are cached in the container.
On the other hand, an instance of stateful service can hold data that influences its behavior. Such services implement IStatefulComponent interface, which introduces init and finish methods, called by the service bus while creating and destroying a service instance. Instantiation and initialisation is performed during node start-up. Stateful services can be also realized as threads, that are started in init method and finished asynchronously while destroying the service.
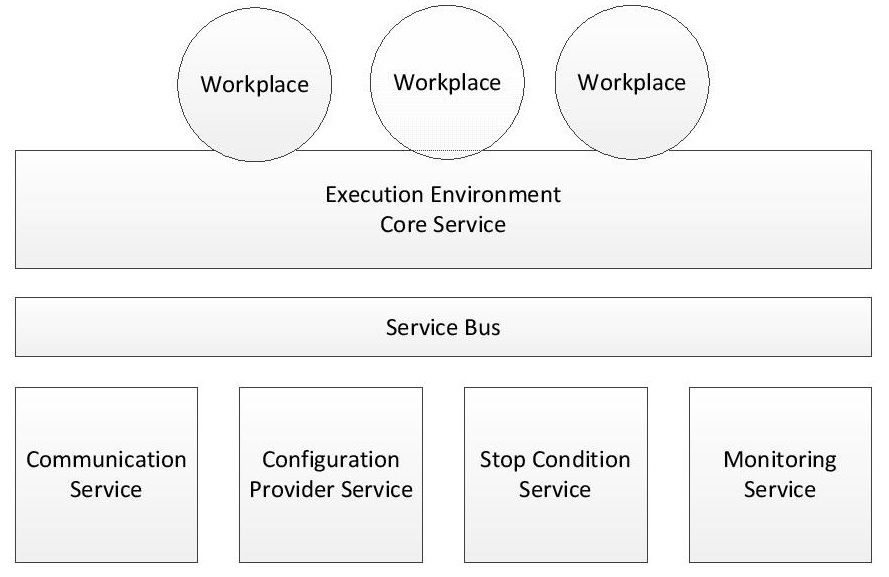
The figure above shows an example node with registered services. The figure distinguish the main service (called core service), which constitutes an execution environment for agents, that provides functionalities such as global addressing schema, communication via message passing, query mechanism, life-cycle management.
This service also plays role of a proxy between agents and other services. Various services provide functionalities related to infrastructure (e.g. communication and configuration provider services), simulation (e.g. stop condition service) or external tools (e.g. monitoring service, which collects and stores simulation data for a visualisation application).
In one distributed environment particular nodes can have different responsibilities such as an end-user console, monitoring, management, and at last execution nodes. The role of a node is specified by the configuration of services plugged into its bus. Also, one can imagine a platform comprised only from a single node that works without any communication services (such configuration is often used for test purposes).
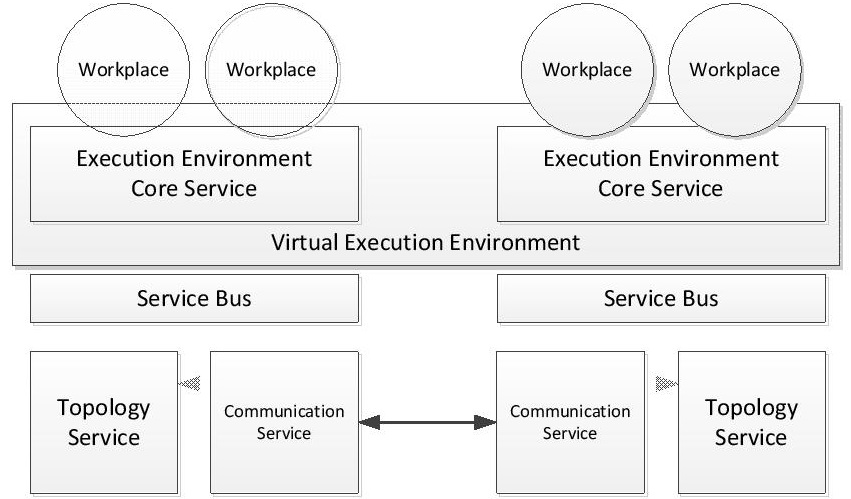
Virtual execution environment
The platform introduces a virtual execution environment in distributed systems that allows for performing operations involving top level agents (workplaces) located on different nodes without their awareness of physical distribution. Such operations are executed by the core service according to Proxy design pattern. The service uses the communication service to communicate with core services located on other nodes. This constitutes a global name space of top level agents in the distributed environment. In other words, the virtual execution environment can be perceived as a realisation of virtual root agent.
The name space of agents can be narrowed by introducing agent neighbourhood that defines visibility of top level agents. An agent can perform operations only on agents from its neighbourhood. The neighbourhood is realized and managed by a topology service (shown in the figure below). This allows for creating virtual topologies among agents on the top of the distributed environment. Various topology strategies such as ring, grid, multi-dimensional grid can be applied in simulations.